





Work Completed By: Chris Jones
DESCRIPTION
We currently publish a wealth of information to our website in Notes databases and web content format. It would be incredibly useful if we could expose this information as web feeds/services without the need for a lot of re-engineering.
There are tools that will facilitate the conversion of web content into other web service formats. Using such methods create a service (or set of services) from information on our web site and then demonstrate how this service can be re-used in a way that wasn’t possible before.
DETAILS/LOCATION OF PRACTICAL DEMONSTRABLE OUTPUT
Details of where code, web pages etc can be found.
This is an RSS feed that screen scrapes our WCC website search facility (via Open Objects), that searches the WCC website for the last 10 entries that mention Cllr Alan Farnell. It has then fed into feedburner in order to access this feed.
Generated Dapper RSS Feed: http://www.dapper.net/services/CllrAlanFarnellRSS
Burned RSS Feed: http://feeds2.feedburner.com/WccCllrAlanFarnellRSS
The below are two iCal calendar feeds were created with Dapper. The first is a screen scrape from the committee admin database, the second is a screen scrap from the Events database.
Source URL:
http://www.warwickshire.gov.uk/corporate/committe.nsf/WmeetdateWCC?openview&CollapseView
Generated Dapper RSS Feed http://www.dapper.net/services/WCCCommitteeCalV3
Generated Dapper RSS Feed http://www.dapper.net/services/WCCEventsV2
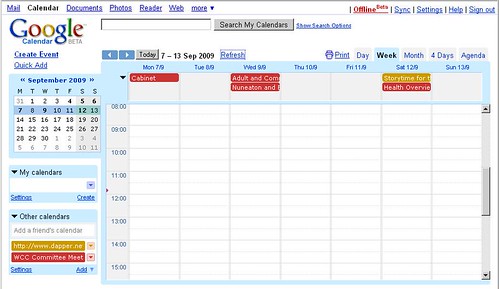
I have then used both these iCal feeds and added them within my Google Calendar and 30boxes.com account. See below pictures for a combined view of both feeds within my Google Calendar (desktop and iPod Touch)

This is an RSS feed created with feed34 that screen scrapes our WCC web site search facility for the last 10 entries that mention Jim Graham.
Generated Feed43 RSS Feed: http://www.feed43.com/jimgraham.xml
This is an RSS feed created with Feedity that screen scrapes our WCC web site search facility for the last 10 entries that mention Alan Farnell.
Generated Feedity RSS Feed: http://feedity.com/rss.aspx/openobjects-com/UlFTVVNX
DESCRIPTION OF THE WORK CARRIED OUT
Describe how you approached this piece of work, any technologies, tools or techniques that you found useful or tried and discarded. Include any examples that you used for inspiration and any contacts you have made in carrying out the work.
Screen scraping does seem like a very useful/generic way we could get information out of our current website and the reuse them as feeds/services, without as suggested above a lot of reengineering of our old Notes Database. With this in mind my research involved investigating various screen scrapping and related services, in order to establish how effective they can be used on our existing website.
FeedBurner (http://www.feedburner.com)
After a bit of research, there appears a number of benefits of ‘burning’ your Feeds through FeedBurner.
1) Keeps statical information including the number of people looking at your feeds.
2) Your feed URL’s never needs to change. Feedburner acts as an intermediary layer so even if your source URL changes (for example because of a new platform sourcing it) the Feedburner URL stays unchanged, only its inputs are modified. This is very important, because if you start changing your RSS URL’s you are like to lose hundreds of readers. Also if you were to create an iPhone application to aggregate RSS feeds, if the RSS URL’s changed then you would have to release a new version of the application.
3) Re-hosts your feed so it takes the stress off your server.
4) There is a SmartFeed option that translates your feed on-the-fly into a format (RSS or Atom) compatible with your visitors’ feed reader application.
5) Now Google have brought out FeedBurner its now free, this includes FeedBurner Stats Pro and MyBrand.
Dapper (http://dapper.net)
What a great start to screen scrapping, makes it an enjoyable process :)
1) You start by entering your starting URL and then you can select from a variety of output formats: Dapp XML, RSS feed, Google Gadget, Netvibes Module, Google Map, iCalendar or Image Lookup (you can always change the output format later) .
2) You can then navigate your chosen source URL page, once there click on the Add to Basket Button, followed by the Next Step button.
3) Dapper then analysis’s your page, before you can start selecting your chosen elements that you want to bring through as fields into the required output. Dapper automatically attempts to select the required id’s for you on selecting a particular element, it is variably not quite right, but you can easily refine the content through this nicely designed interface. One down side is it can be a little on the slow side, but maybe that‘s the price of having such a graphical intuitive interface.
4) You then preview the feed extracted content before you confirm its ok and save the feed. On saving it appears to get an error “rest client not null”?? however if you return to the dapper home page and click on “My Accounts and Dapps” you will see your newly created Dapp.
5) From this newly created Dapp you can then create the following format feeds; XML, RSS Feed, Filtered RSS Feed, HTML, Google Gadget, Netvibes Module, PageFlake, Google Map, Image Loop, iCalendar, Aton Feed, CSV, JSON, XSL, YAML and Email. Not that I’ve tried all of them, but it seems a pretty comprehensive list.
Free Licence – Throughput, Best effort. No more than 1 hit per second/No Redundancy guaranteed/Support - Email
Premium Licence – Throughput – Best effort. Shared sever with up to 10 other customers. No enforced cap on burst usage/ Support - Email and phone support within three business days.
Pro Licence – Throughput – Dedicated server with no cap on usage/Redundancy – Hot swappable dedicated backup server/ Support – Email and phone support on next business day.
Feed43 (http://www.feed43.com)
This is another web service to generate RSS feeds via screen scrapping. This one did not include any nice gui interface like dapper. So it was a case of extracting the feed directly from the html tags. Took a little bit longer to setup but eventually created a RSS feed based on a Search for “Jim Graham” by date from our websites search facility. See above section for link to RSS feed. Again only generates RSS feeds.
Free Licence – Unlimited Feeds/20 items per feed/6 hour feed update interval/Max page size 100KB
Paid 20 Licence $29 a year – Unlimited Free Feeds/20 paid Feeds/1 hour feed update interval/Max page size 250KB
Paid 50 Licence $49 a year – Unlimited Free Feeds/50 paid Feeds/1 hour feed update interval/Max page size 250KB
Paid 100 Licence $98 a year – Unlimited Free Feeds/10 paid Feeds/1 hour feed update interval/Max page size 250KB
Feedity (http://feedity.com)
Feedity responded to a twitter regarding screen scrapping services (good start). Had a quick play with their service. Very quick to setup RSS feeds. Although it didn’t seem that intuitive to refine the RSS Feed. Also in order to retrieve published dates you need to sign up to the paid Pro Plan. RSS feed only.
Free Licence – 10 Feeds/15 items per feed/5 hours Feed update interval/No uptime guarantee
Premium Licence $39 a year – 50 Feeds/30 items per feed/90 minutes feed update interval/99% uptime guarantee
Pro Licence $369 a year - 100 Feeds/100 items per feed/30 minutes feed update interval/99.5% uptime guarantee
PROJECT OUTCOME
Describe the degree to which the work was successful in addressing the project description. Include reasons why or why not.
I had reasonable success screen scraping the WCC search results pages and the committee admin meetings database. With the WCC search results page you first generated a search say ‘Jim Graham’, then selected it into date order. This then became the base URL for screen scrapping the last 10 entries on a particular search word. With the committee admin meetings database there was already a view that could be used as a basis for screen scrapping, from this I creating a iCal feed which I then managed to expose within Google Calendar and 30Boxes.com.
I tried a number of other databases on our website, such as the Job Vacancies, Consultation database and Mobile Libraries database however due to the format of the views (i.e. categorised) it was difficult to get the required output. A way around this would be to make a source view within the Notes database which could then been used specifically to create web feeds/services, although this is a change to a Notes Database it is not a big/risky change so could be implemented reasonable fast.
I also tried extracting recycling centres information from the sites main content management database (i.e. web pages). This involved creating a simple feed for each recycling centre web page. I was then planning to merge these feeds together using Yahoo Pipes, but decided the whole idea would be unfeasible as any changes to these pages (which would be outside our control) would probably break the feed.
It’s unfortunate, but certain data within our website that would really benefit from using screen scraping tools are being stored in the completely the wrong format e.g. Images. There may well be a screen scraper out there that can OCR the content, but it doesn’t sound a good idea and it would probably be better if they just displayed this data in a different way. Two great examples of where we could of used a screen scraper to extract the content (and then maybe even display the content in maps) if they were not stored as Images are shown below (its truly shocking and far from accessible):
Speed Limit Review (tables of data shown as images)
http://www.warwickshire.gov.uk/Web/corporate/pages.nsf/Links/E975F970ACA51B95802574E40034FEAF
http://www.warwickshire.gov.uk/Web/corporate/pages.nsf/Links/5491D3161AE3A751802574E40034F0B8
http://www.warwickshire.gov.uk/Web/Corporate/Pages.nsf/Links/4CBCA5294BD637C8802574E40034E787
http://www.warwickshire.gov.uk/Web/corporate/pages.nsf/Links/5829AFFD382576A8802574E40034DA99
http://www.warwickshire.gov.uk/Web/corporate/pages.nsf/Links/4E449503DC480801802574E40034C920
Safety Cameras in Warwickshire (tables of data shown as images)
http://www.warwickshire.gov.uk/Web/corporate/pages.nsf/Links/A6BB64117DDDF18780256B67003F8DF7
http://www.warwickshire.gov.uk/Web/corporate/pages.nsf/Links/33B566B2CF68769480256B670041DBF2
http://www.warwickshire.gov.uk/Web/corporate/pages.nsf/Links/447D4C2060DAD00780256B670042E321
http://www.warwickshire.gov.uk/Web/corporate/pages.nsf/Links/3D996568AA6F1F2280256B670046D3FA
http://www.warwickshire.gov.uk/Web/corporate/pages.nsf/Links/5BF3FBC04A840CFF80256B670045DC91
SHORT TERM BENEFITS
What immediate impact could the output of this R&D work have on the organisation – could it provide benefits without compromising our strategic approach?
- Create RSS feeds off search result pages. For example when selecting a particular councillor web page, you could also provide an RSS feed of all the latest pages on our website that include their name.
- You could take the above step even further and create a screen scrap of news from all the local news papers as well. Then using Yahoo pipes combine them all together and create a filter based on the councillors name. This would provide a complete RSS feed for the councillor that includes anything on our own website and also within the local media.
- Add Notes web views specifically for use as source URL feeds. Databases such as the job vacancies database, Consultation database , Mobile libraries database and Committee admin databases would be a good start. You could then use a screen scraper to generate various RSS/XML feeds. Also using dapper/FeedBurner you could generate JSON/ATOM feeds that could be used within the new iPhone application.
- Create a number of useful iCal feeds from information on our website such as, committee admin meetings, events, job vacancies closing date, consultation database and possibly mobile library stop dates? Users can then add one or many different WCC iCal services to there personal calendars.
STRATEGIC IMPLICATIONS
How the work carried out fits with our strategic direction or how it should contribute to our strategic thinking.
Screen scrapping our website for various feeds could be a good way to quickly provide useful feeds to our website. Also as the majority of the work will be done outside of our legacy domino applications, this should make it easier and more transparent when migrating these new services to other platforms.



